# 第 1 题-http 请求方式有哪几种?
HTTP1.0 定义了三种请求方法: GET,POST,HEAD方法
HTTP1.1 新增了五种请求方法: OPTIONS,PUT,DELETE,TRACR,CONNECT方法
- get: 请求指定的页面信息,并返回实体主体
- HEAD: 类似 get 请求,只不过返回的响应中没有具体内容,用于获取报头
- POST:向指定资源提交数据进行处理请求(如表单提交或上传文件),数据被包含在请求体中
- put: 向指定资源位置上传其最新的内容
- DELETE: 请求服务器删除
Request-url所标识的资源 - TRACE: 回显服务器收到的请求,主要用于测试或诊断
- CONNECT:预留给能够将连接改为管道方式的代理服务器
# 第 2 题-http 中 get 与 post 有什么区别?
区别: get请求无消息体,只能携带少量数据,post请求有消息体,可以携带大量数据
携带数据的方式
get请求将数据放在url地止中,也就是http请求协议头中post请求将数据放在body请求体中get方式提交的数据大概是 1M,而post没有限制
# 第 3 题-HTTP 与 HTTPS 有什么区别?
文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容
不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP 协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决 HTTP 协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议 HTTPS,为了数据传输的安全,HTTPS 在 HTTP 的基础上加入了 SSL 协议,SSL 依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密
HTTPS 协议主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全,另一种就是确认网站的真实性
区别: HTTP 协议传输的数据都是未加密的,也就是明文的
HTTPS: 该协议是由SSL+HTTP协议构建的可进行加密传输,身份认证的网络协议,要比 http 协议安全
https协议需要ca申请证书,一般免费的证书较少,因而需要一定的费用http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议http和https使用的是完全不同的连接方式,用的端口也不一样,http是80,https是 443http的连接很简单,是无状态的,https协议是由ssl+http协议构建的课进行加密传输,身份认证的网络协议,比http协议安全
# 第 4 题-强缓存与协商缓存
缓存的优点:
- 减少了不必要的数据传输,节省带宽
- 减少服务器的负担,提升网站性能
- 加快了客户端加载网页的速度
- 用户体验友好
缺点:
- 资源如果更改,但是客户端不及时更新就会造成用户获取信息滞后
当浏览器去请求某个文件的时候,服务端就在respone header里面对该文件做了缓存配置。缓存的时间、缓存类型都由服务端控制
浏览器第一次请求时
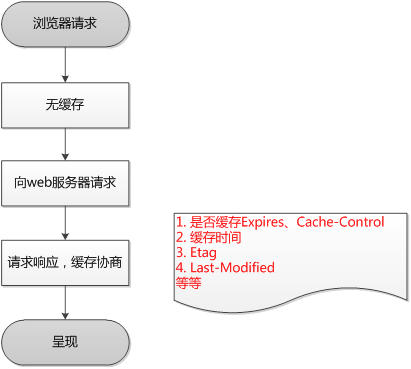
浏览器后续在进行请求时
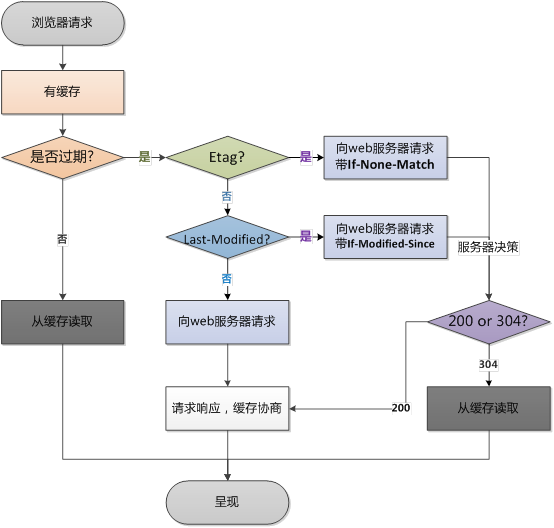
从上图可以知道,浏览器缓存包括两种类型,即强缓存(本地缓存)和协商缓存,浏览器在第一次请求发生后,再次请求时
- 浏览器在请求某一资源时,会先获取该资源缓存的
header信息,判断是否命中强缓存(cache-control)和expires信息,若命中,直接从缓存中获取资源信息,包括缓存header信息,本次请求根本就不会与服务器进行通信 请求头信息
* Accept: ""
* Accept-Encoding: gzip,deflate
* Accept-Language:zh-cn
* Connection: keep-alive
* Host
* Referer
* User-Agent
2
3
4
5
6
7
来自缓存的响应头的信息
Accept-Ranges: bytes
Cache-Control: max-age= xxxx
Content-Encoding: gzip
Content-length: 3333
Content-Type: application/javascript
Date:xxx
Expires: xxx
Last-Modified:xxx
Server: 服务器
....
2
3
4
5
6
7
8
9
10
- 如果没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的
header字段信息(Last-Modified/If-Modified-Since和Etag/If-None-Match),由服务器根据请求中的相关header信息来比对结果是否协商缓存命中,若命中,则服务器返回新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取,否则返回最新的资源内容
强缓存与协商缓存的区别,如下所示
| 获取资源形式 | 状态码 | |
|---|---|---|
| 强缓存 | 从缓存取 | 200 |
| 协商缓存 | 从缓存取 | 304 |
强缓存相关的header字段
强缓存是直接从缓存中获取资源而不经过服务器,与强缓存相关的header字段有两个
expires:这是http1.0的规范,它的值为一个绝对时间的 GMT 格式的时间字符串,如Mon, 15 Jun 2029 20:08:12 GMT,如果发送请求的时间在expires之前,那么本地缓存始终有效,否则就会发送请求到服务器来获取资源cache-control:max-age=number,这是http1.1时出现的header信息,主要利用该字段的max-age值来进行判断,它是一个相对值,资源第一次请求时间和Cache-Control设定有效期,计算出一个资源过期时间,在拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则就不行,cache-control除了该字段外,还有下面几个比较常用的设置值
no-cache: 不使用本地缓存,需要使用协商缓存,先与服务器确认返回的响应是否被更改,如果之前中存在ETag,那么请求的时候会与服务器验证,如果资源未被更改,则可以避免重新下载no-store: 直接禁止浏览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源- public: 可以被所有的用户缓存,包括终端用户和 cdn 等中间代理服务器
- private: 只能被终端用户的浏览器缓存,不允许 cdn 等中缓存服务器对其缓存
注意
如果cache-control与expires同时存在的话,cache-control的优先级高于expires
协商缓存相关的 header 字段
协商缓存都是由服务器来确定缓存资源是否可用的,所以客户端与服务器端需要某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问,这主要涉及到下面两组 header 字段
这两组搭档都是成对出现的,即第一次请求的响应头带上某个字段(Last-Modified 或 Etag),则后续请求则会带上对应的请求字段(If-Modified-Since 或 If-Node-Match),若响应头没有Last-Modified或Etag字段,则请求头也不会由对应的字段
- Last-Modified/If-Modified-Since 二者的值都是 GMT 格式的时间字符串,具体过程
- 浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在
response的header加上Last-Modified的header,这个header表示这个资源在服务器上的最后修改时间 - 浏览器再次跟服务器请求这个资源时,在
request的header上加上If-Modified-Since的header,这个header的值就是上一次请求时返回的Last-Modified的值 - 服务器再次收到资源请求时,根据浏览器传过来的
If-Modified-Since和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化则返回 304 Not Modified,但是不会返回资源内容,如果有变化,就正常返回资源内容,当服务器返回 304 Not Modified 的响应时,response header 中不会再添加 Last-Modified 的 header,因为既然资源没有变化,那么Last-Modified也就不会改变,这是服务器返回 304 的 response header - 浏览器收到 304 的响应后,就会从缓存中加载资源
- 如果协商缓存没有命中,浏览器直接从服务器加载资源时,Last-Modified 的 Header 在重新加载的时候会被更新,下次请求时,If-Modified-Since 会启用上次返回的 Last-Modifed 的值
- Etag/If-None-Match
这两个值是由服务器生成的每个资源的唯一标识符,只要资源有变化,这个值就会改变,其判断过程与Last-Modified/If-Modified-Since类似,与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前没有变化
既有Last-Modified又为何有ETag
使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,那为什么还需要Etag呢,HTTP1.1 中ETag的出现主要时为了解决几个Last-Modified比较难解决的问题
- 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候,我们并不希望客户端认为这个文件被修改了,而重新 get
- 某些文件修改非常频繁,比如在秒以下的时间内进行修改(比方说 1s 内修改了 N 次),
If-Modified-Since能检查到的粒度时 s 级的,这种修改无法判断(或者说 UNIX 记录 MTIME 只能精确到秒) - 某些服务器不能精确得到的文件的最后修改时间
这时,利用ETag能够更加准确的控制缓存,因为ETag时服务器自动生成或由开发者生成对应资源在服务器端的唯一的标识符
Last-Modified 与 ETag 是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304
← 目录


